Flexible HA & Scalability Architectures with Payara Server
Payara
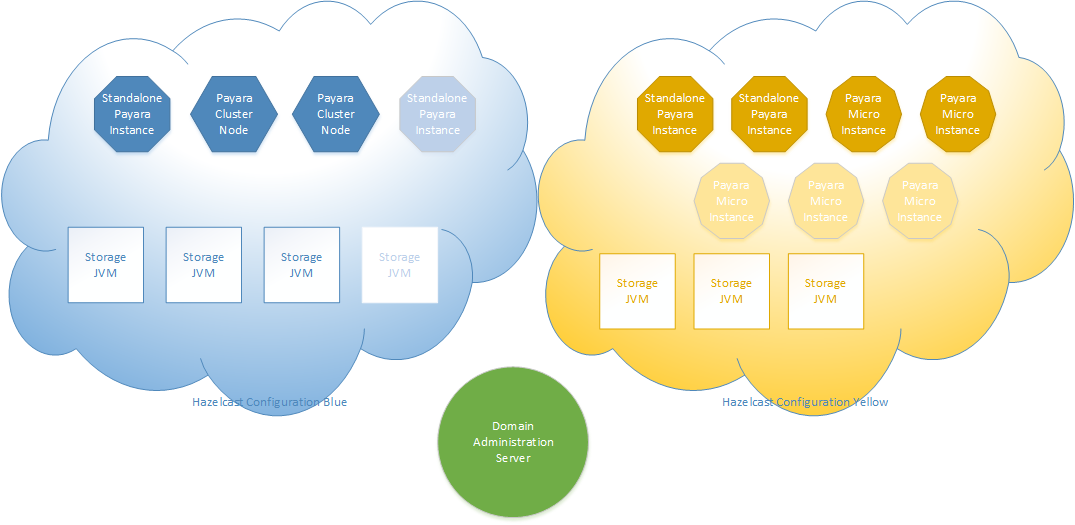
One of the lesser known features and key benefits of Payara Server is that it provides huge flexibility when architecting topologies for High Availability and Scalability. Utilising the embedded Hazelcast Data Grid for web session and JCache clustering brings the potential of many different topologies for scale out.

An example of some of the possible topologies is shown in the image above. The example shows two Hazelcast configurations – yellow and blue. Within a single configuration JCache and Web Session data is stored in all nodes within the same colour. In the image, nodes with a solid fill are hosting the application, nodes with no fill are in-memory data storage JVMs. The Payara Server instance types are shown within each node. Nodes with a lighter fill can be switched on or off, depending on the application load, to give elastic scalability. The topology is completely independent of the deployment across a number of physical host machines and could be spread across a number of physical hosts.
In the possible architecture visual you can see that storage of web session or cache data can be spread across more virtual machines than the application deployment. Also, web session and cache data can be stored in memory in non-Payara Server, or Payara Micro virtual machines. This gives great scalability advantages to technical architects designing Payara Server topologies.
By placing cluster data in additional virtual machines the availability of the data and the number of virtual machines is decoupled from the application deployment. This enables operations teams to completely take down an application without losing application data, or to devise rolling upgrade scenarios safe in the knowledge that no data will be lost.

Secondly, by using dedicated JVMs for storing application data in memory, the garbage collection ergonomics of these storage JVMs can be tuned for long term data storage with large old generations, whereas the application JVMs garbage collection can be tuned for high throughput.
Finally, with the “auto-clustering” capabilities of Payara Server, additional storage nodes or application processing nodes can be added on demand to increase scalability as the in-memory data needs grow.
Creating a shared Hazelcast configuration (one of the colours above) is as simple as ensuring your Payara Micro, Payara Standalone and Payara Server cluster instances all have the same Hazelcast configuration in the administration console.
CONCLUSION:
With Payara Server and Payara Micro you are not limited to traditional cluster architectures to scale out your web session and JCache data. Flexible in-memory data storage options are available without ever creating a traditional “cluster”. Further additional capabilities for WAN replication and high density memory storage are available with Payara Scales.

Share:

 1 minute
1 minute
Modern high-frequency trading (HFT) platforms operate under extreme performance constraints, processing tens of thousands of messages per second while […]
 1 minute
1 minute
Earlier this week, we’ve launched the 2026 Payara Platform Community Survey and we’d love to hear from you. If […]
 8 minutes
8 minutes
Jakarta EE applications can take anywhere from several seconds to over a minute to start, depending on their size […]
Hello, Steve. Very interesting. Payara Micro is really fine, but the only thing I would like to also see in PayaraMicro is JMS support. I’ve noticed that it is possible to make custom build of PM because it is open source. Could you please tell me which artifacts should I add to pom.xml to do that?
Note I haven’t tested this.
My first thought would be to take copy of the embedded-all module
https://github.com/payara/Payara/blob/master/appserver/extras/embedded/all/
Then add in the specific Payara Micro dependencies from the payara-micro pom
Request for user/admin guide for both full/micro.