Creating a Simple Cluster with Payara Server 4
Uncategorized
GlassFish has traditionally used Project Shoal to power its clusters. Since Shoal is no longer actively maintained, Payara Server intends to replace Shoal with Hazelcast, which has the added benefit of being JCache compliant.
Note: this blog post is relevant for Payara Server 4. If you’re using Payara Server 5, you’ll want to learn about the automatic clustering with deployment groups:
The simplest kind of cluster with Payara Server involves a Domain Administration Server (DAS) and two or more standalone instances that share the same configuration. The standalone instances may run on remote machines, but we will make it simple and run them on the same machine, occupying different ports.
A cluster is a group of application servers that transparently run applications as if they were a single entity. Therefore, a cluster is able to support much more load than a single server. It allows for the provision of extra capacity by adding more servers when needed, effectively scaling the application on demand.
Additional servers also makes the application highly available, because it allows it to run on multiple independent nodes and thus allowing the take-over of a failed instance by another node.
Payara Server also provides replication among members of the cluster. It is possible to turn on automatic replication of web sessions, stateful session beans as well as cached data. This prevents data loss if any member of a cluster fails. In such a case, the data is automatically available to other instances which can transparently take over.
First, we will create 2 standalone instances that share the same configuration. There are two ways to do it, both very simple.
First approach is to create an instance first:
We will use admin console to perform the steps, although the same can be achieved by the asadmin utility.
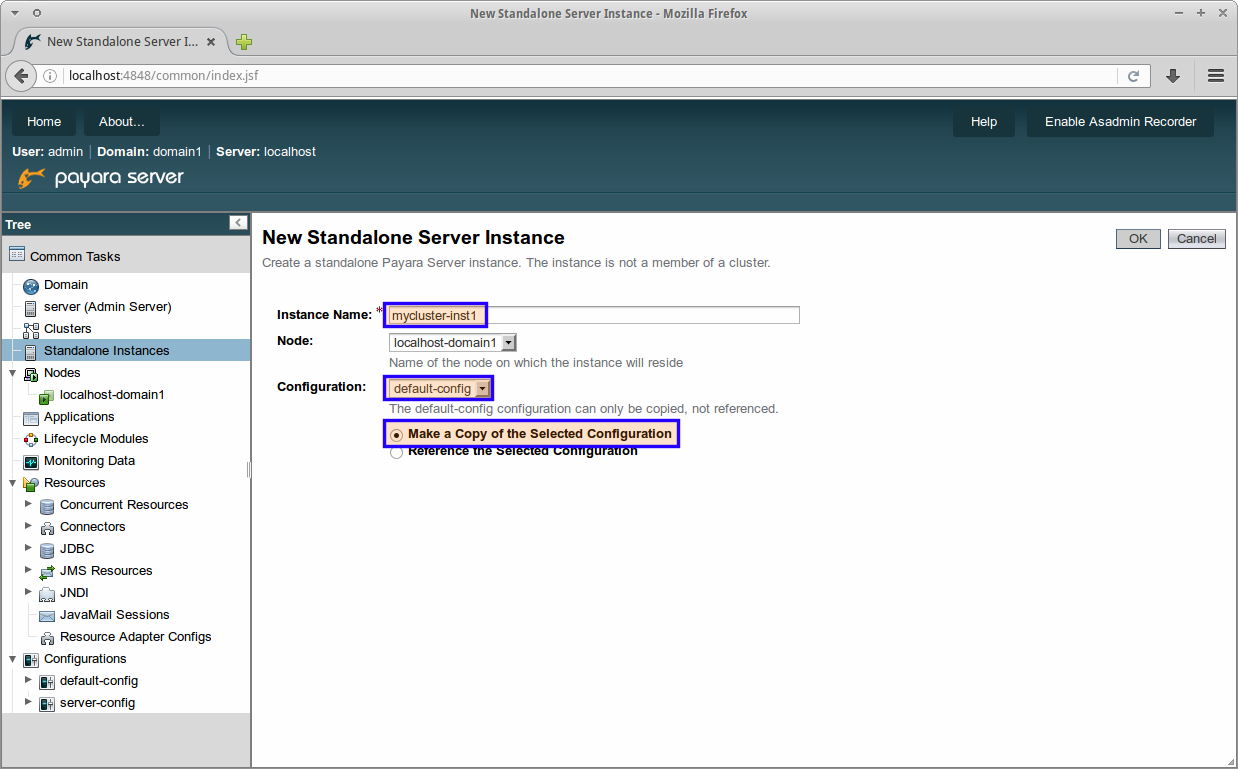
To create a standalone instance, we will go to the section called Standalone instances, and press the New… button.

We will give our instance a name and copy the configuration from default-config. The new instance will run on a predefined node at localhost.
To create a second instance (and any subsequent instances), we will again create a new standalone instance as in the previous step. But now, we will make it reference the configuration of the first instance.

Alternatively, we may copy the configuration first, allowing us to give it a more suitable name:

Once the instances are created, we need to enable Hazelcast replication:
Hazelcast configuration is available in the Hazelcast tab of a standalone instance:
Note, that this configures Hazelcast for every instance which references the same configuration. This is a bit confusing so, in the 162 release, the configuration of Hazelcast has been moved from an instance tab to a section within the configuration.
To configure replication of web sessions and session beans, open the Availability Service section. Then select hazelcast as the Persistence Type in the Web Container Availability tab. Ensure that Availability Service is enabled on this tab.

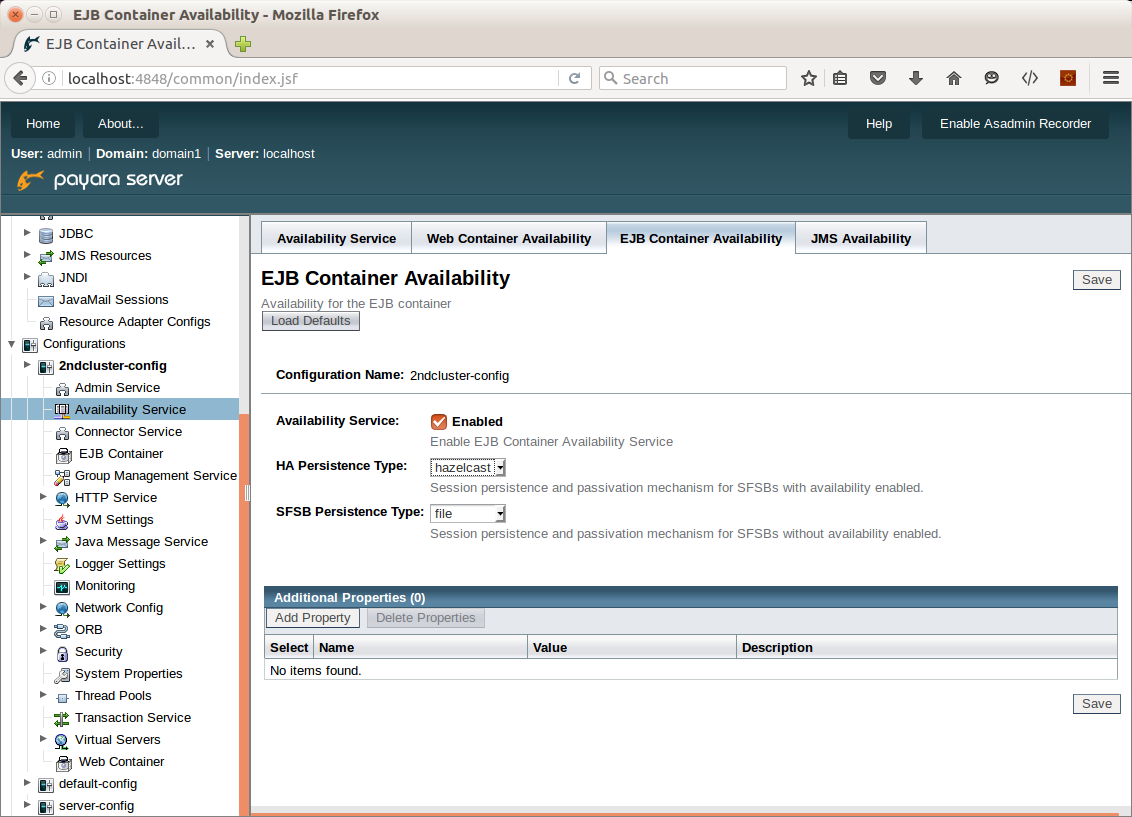
In the EJB Container Availability tab, select hazelcast as HA Persistence Type and ensure that Availability Service is enabled.
We’ve created a very simple cluster, with only 2 instances, both running on the same machine. In order to make the cluster appear as a single transparent server to the outside world, we still need to add a load balancer to the game, which will act as a gateway to the instances of the cluster.
We may later extend our cluster to remote machines and run instances on additional remote nodes. We may go even further; Payara Server clustering based on Hazelcast opens various options beyond traditional clustering. It allows running heterogeneous instances with different deployed applications and configuring where and how the data is replicated. It is even possible to combine Payara Server and Payara Micro instances in the same cluster, opening a smooth transition path to a microservice architecture.
Find out more about Payara Server’s scaling & clustering capabilities.
{{cta(‘4c7626f5-1e53-418e-90c8-add6e4af19c9’)}}
Share:

 7 minutes
7 minutes
Modernizing enterprise applications is a strategic imperative for organizations that want to remain competitive and resilient. According to our […]
 5 minutes
5 minutes
At Devoxx Belgium 2025, I was able to talk about what happens after you build your container. In theory, […]
 6 minutes
6 minutes
At the latest Conf42 Internet of Things (IoT) 2024 conference, our Payarans deliver a keynote, titled “At the Edge […]
I’ve been looking into Payara clustering, going through lots of references people have made available. A few things I found which are essential to get apps working but at the same time found few references to are:
First, using asadmin validate-multicast to validate communication between the instances – especially the instructions in the description that says “You should run this subcommand at the same time on each of the hosts to be validated”!
Second, using in your web.xml. This is required otherwise session replication won’t work.
Third, making a glassfish-web.xml with the following domain specified otherwise session replication wont’ work.
Finally, if you have Glassfish Admin console open, use a **different** browser to check your application otherwise cookies get mixed up and it looks like session replication isn’t working.
Michael,
I am trying to get Session replication to work in my Payara cluster.
Would you please help me understand what you learned?
1. What did you mean by “using in your web.xml”?
2. You wrote “making a glassfish-web.xml with the following domain specified”. I think something is missing from your post. Could you describe what should be in the glassfish-web.xml file?
Thank You
How to create high-availability cluster with 2 nodes?
It looks like the XML tags of my post got stripped out. So I’ll try this again and of course you’ll need to translate this into XML
First, for web.xml, make sure you have the right version of the spec defined for EE7.
[web-app version=”2.4″ xmlns=”http://java.sun.com/xml/ns/j2ee” xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance” xsi:schemaLocation=”http://java.sun.com/xml/ns/j2ee http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd“]
Also for the web.xml file, you need to have the [distributable/] XML tag. Without it, I found the session replication did not work.
Finally, for the glassfish-web.xml, again make sure you have the right version by declaring the DOCTYPE. And, you need to add a “cookieDomain” property where the value of this propery is the domain of your application (i.e. the URL you use to access it). I found that without this set too, session replication didn’t work either. So here’s an example:
[?xml version=”1.0″ encoding=”UTF-8″?]
[!DOCTYPE glassfish-web-app PUBLIC “-//GlassFish.org//DTD GlassFish Application Server 3.1 Servlet 3.0//EN” “http://glassfish.org/dtds/glassfish-web-app_3_0-1.dtd”]
[glassfish-web-app error-url=””]
[session-config]
[cookie-properties]
[property name=”cookieDomain” value=”com.company”/]
[/cookie-properties]
[/session-config]
[/glassfish-web-app]
Email me directly if you have any more questions: mjremijan at yahoo
Thank you Michael Remijan.
My simple cluster is now working with Session replication!
Next step is a proper load balancer.
I created a simple cluster with 3 nodes on LAN
The host names of the nodes have been renamed as “n1.test.com”,”n2.test.com”,”n3.test.com”
I enabled Hazelcast on the cluster config and i selected “Hazelcast” as persistence type on the Web container Availability tab.
In the application :
the tag distributable has been added in the web.xml
cookie domain has been added in the glassfish-web.xml with the value “test.com”
The n1 and n2 nodes works well ,indeed when i open or/and refresh a page on these nodes the session is shared and is the same. When i load the page on the third node the session is destroyed and re-created.
Can you help me?
I haven’t worked with Hazelcast so that may be an issue. I’d suggest complely recreating n3 an d see if that helps.
Luca,
This may be unrelated but I can tell you when I started testing with my simple cluster I found the Session was lost each time I loaded a certain page.
After investigation I narrowed it down to calling session.setAttribute() with a plain Java array of objects (like MyObject[]).
I updated my code to store the collection in the Session using an ArrayList instead of plain array and that fixed the issue.
I suspect that Hazelcast was not designed to hanlde plain arrays?
I hope this helps someone who may have the same issue.
I tried several times but it doesn’t work. it is very strange!
Hi Michael,
my test application it’s very easy. it shows only the SessionID on the Index.xhtml, N1 & N2 are syncrhonized but when i load index.xhtml on node N3 the SessionID change. Consequently when i reload the page on other nodes these shows the new SessionID (created by N3).
Hello,
after deploy application, session replication works fine. But, after restart an instance, i got this error in every http request:
java.lang.NullPointerException
at org.glassfish.web.ha.session.management.ReplicationStore.doValveSave(ReplicationStore.java:199)
And, session replication stops work. Could you help me?
I’d very much like your notes on load balancing configuration. Please post or email to me, thanks!
Does glassfish / payara rely on Catalina and its JSESSIONIDVERSION cookie when supporting web session persistence in a Hazelcast backed web farm?
https://github.com/payara/Payara/search?utf8=%E2%9C%93&q=jsessionidversion
It would be nice to avoid the Set-Cookie to the “JSESSIONIDVERSION” cookie on every web request/response.
Thoughts?
As a followup to my earlier comments, I’ve put together a blog post titled “High Availability (HA), Session Replicated, Multi-VM Payara Cluster – The (Almost) Complete Guide”. It’s available at http://blog.payara.fish/creating-a-simple-cluster-with-payara-server and it steps the reader through steps to create a High Availability (HA), load balanced, session replicated, multi-machined Payara/GlassFish cluster with 2 nodes and 4 instances
can you give me you application of clusterTest to see your configuration ,I use my application can not realize demonstrate session persistence
Hi Cory,
I am glad that this article has brought me this far, however i have noticed a problem with the logs on the instances, I have deployed an application to the cluster but I don’t seem to see the logs running. Please advise
Hello Mike and hello everyone,
Do you think it is possible to create DAS and clusters (datagrid) using the asadmin tool? For example, when I extend a dockerfile, I would like to create my DAS and cluster directly on it without having to reconfigure it each time the container is started.
Thanking you in advance
Yes it is possible to create and configure the Data Grid using asadmin commands. All the asadmin commands are documented in our documentation https://docs.payara.fish/documentation/payara-server/hazelcast/configuration.html